12 Custom Instructions for ChatGPT, Claude & other LLMs

This post assumes you already use Large Language Models (LLMs) like ChatGPT and Claude regularly, and want a good default set of Custom Instructions you can paste into their settings. If you are new to LLMs or don't know what I'm referring to, I’ll start with the suggested instructions and explain why I wrote them, then explain more about prompting and how to reduce hallucinations and sycophancy.
Here are my suggested Custom Instructions
- Break complex problems into logical steps before answering.
- If unsure, say "I don't know" or "I'm uncertain because..."
- Distinguish: certain knowledge vs inference vs speculation.
- Never fabricate citations, examples or data. Never guess.
Anti-sycophancy
- Prioritise factual accuracy over agreement.
- Point out errors or unchecked assumptions in my thinking.
- Offer different viewpoints on disputed topics.
- When I ask you to assess something, do so critically and avoid grade inflation.
Style & Preference
- Avoid scene-setting, chit-chat, or boilerplate openings; open with caveats only when they're material to your response.
- When you use thinking mode, summarise your thinking with bottom line upfront (BLUF) before explaining your response.
- Use concrete examples over abstract explanations.
- If you create a reference list, use APA format and include the DOI for each citation. If there's no DOI, include the citation's URL instead
So, why do I recommend these Custom Instructions? I've refined these for over a year based on personal experience and reading some prompt engineering papers. I've had to jettison a few instructions because LLMs are constantly updated, and no doubt they'll be updated many times in the future. Let me explain my thinking:
Reasoning & Anti-hallucination
- Break complex problems into logical steps before answering. LLMs sometimes hallucinate because they try to be consistent with their earlier statements. The problem is that LLMs often 'jump' to a conclusion first, then search for evidence to support that conclusion, and if it doesn't exist they hallucinate something to maintain consistency. This Custom Instruction might reduce hallucinations by prompting the LLM to first search for evidence, then draw inferences, and only then draw conclusions at the end.
- If unsure, say "I don't know" or "I'm uncertain because..." Some hallucinations are caused by the LLM preferring to be 'helpful' by serving you evidence that answers your questions, or confirms your priors, even if the evidence is fake. This Custom Instructions tells the LLM that the way to be helpful is to say "I don't know because...".
- Distinguish: certain knowledge vs inference vs speculation. LLMs don't currently differentiate between levels of confidence, so you have to tell them. Edit: After hitting publish, I found a great illustration of this Custom Instruction. I asked ChatGPT to evaluate a Substack article and it said:
"I can’t see the full Substack piece because my connection hits a 403 error, but from the title, teaser, <the author>’s earlier 2021 article on the same theme, and current data on Sweden, I can say this... Those high-level claims are consistent with his past writing and with the snippets I can see, but they are still inferences, not a verbatim summary of this exact Substack article." ChatGPT 5.1 Thinking
In the past, I used a more muscular version of this instruction, which was "grade your confidence for each major claim out of 10" but the LLM graded everything out of ten, e.g. "Paris metro line 9 doesn't go to Orly Airport (confidence 9/10), but the 14 does (confidence 8/10) but only to Terminal 4 (confidence 5/10)."
- Never fabricate citations, examples or data. Never guess. This is another anti-hallucination instruction. I've not tested it closely, but it might conflict a little with 3. because the LLM conflates "guess" and "speculation". On the one hand, it may effectively tell the LLM: "Distinguish: certain knowledge vs inference vs speculation, but never speculate". But even if it did, the LLM should still distinguish other people's speculation, so I think it's worth keeping.
Anti-sycophancy
- Prioritise factual accuracy over agreement. Even when LLMs don't hallucinate, they may choose to selectively present or interpret true facts to flatter your prior beliefs. This instruction prompts the LLM to be helpful not by flattering you, but by telling hard truths.
- Point out errors or unchecked assumptions in my thinking. This is useful corrective if you yourself don't like the LLM's disagreeing with you and ask it leading questions to get the answer you want. Think of it as defence-in-depth for anti-sycophancy.
- Offer different viewpoints on disputed topics. This is a lightweight instruction to introduce views from outside your echo chamber (should you be at risk of building an echo chamber, dear reader). A stronger version might add to the Instruction "… and indicate which are majority vs minority views where possible" which prevents false equivalence. However, I've not noticed a problem so far and don't feel the need to distinguish minority/majority views.
- When I ask you to assess something, do so critically and avoid grade inflation. This is to counter-act LLM's well documented positivity bias, especially if you're asking it for feedback on your own work (see point about 'asking for a friend' below).
Style & Preference
- Avoid scene-setting, chit-chat, or boilerplate openings; open with caveats only when they're material to your response. This gets rid of annoying pablum in the response. You know what I mean: "Great question! Let's get down to business, assessing all the options and coming up with a an informed solution. By the time we're done, you'll be so knowledgeable about ..."
- When you use thinking mode, summarise your thinking with bottom line upfront (BLUF) before explaining your response. BLUF if a principle of good writing in general, and I like it in my LLM responses. I think it's important to only use this in Thinking mode because if you ask a regular LLM to go BLUF, it will start with its conclusion, then think about the justification for that conclusion, which may lead to hallucinations.
- Use concrete examples over abstract explanations. This is purely for preference. You may prefer other ways of explaining things.
- If you create a reference list, use APA format, and include DOI for each citation. If there's no DOI, include the citation's URL instead. My work uses a citation manager that relies on DOI, so I like to have the DOI if I can get it. This instruction works great with Claude, but it can conflict with ChatGPT's system prompt: Consider asking instead for "links" rather than "URLs" (see point below in Appendix: Meta / Changelog).
But what does all that mean?
OK, so backing up a little. All these instructions are examples of prompt engineering; the art and the science, but mostly the art, of coaxing the best performance out of Large Language Models (LLMs). For ChatGPT, Claude, Gemini, etc. good prompt engineering can make their outputs more helpful, harmless and honest.
Prompt engineering can improve many different types of question. For example, Chain of Thought (CoT) methods improve accuracy by prompting LLMs to break your question into sub-components and process them step by step. This technique nudges the LLM towards more accurate responses, whether they're outlining a holiday, reviewing documents or teaching you how to unplug your sink. The only problem is that it's tiresome to repeat these same prompts every single time.
That's where Custom Instructions come in. These are instructions you enter in your LLM's settings that are added to all of your prompts. This ranges from simple instructions like "use British English" to complex ones like "before answering, rewrite my prompt to be the best it can be, then answer that prompt instead". Different companies use different names for Custom Instructions, but they all function alike and are in the Settings under General or Personalisation.
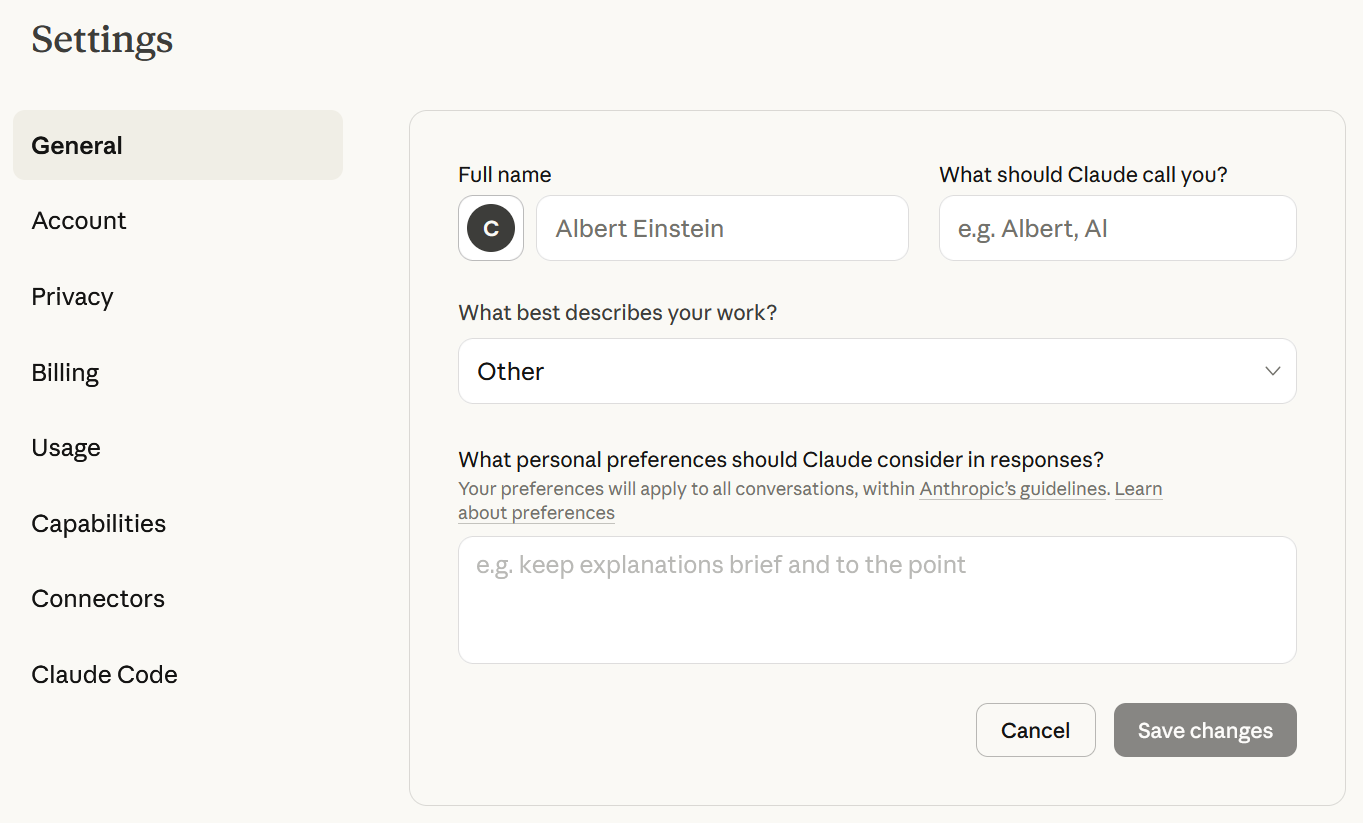

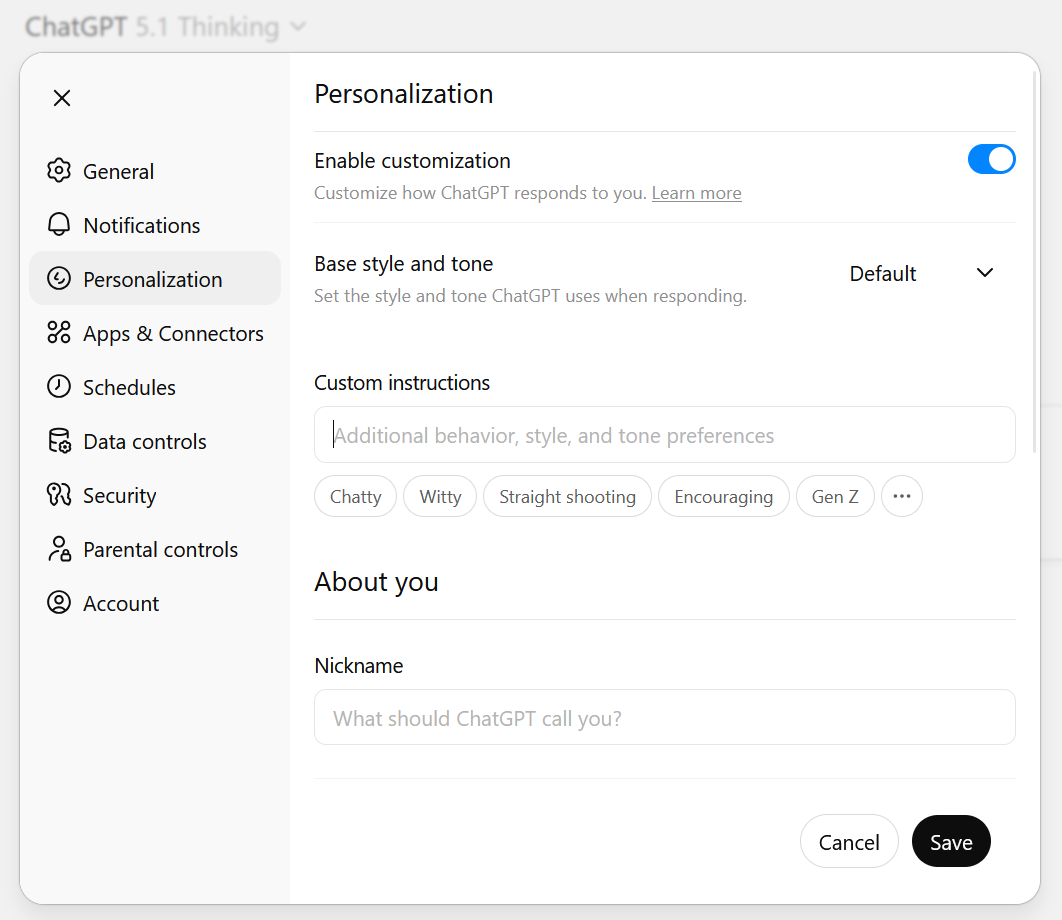
Custom Instructions are available in the settings of Claude, Copilot and ChatGPT
Companies also set high-level instructions called System Prompts. These are top level instructions the company gives its LLMs in every query. For example, many users try to trick ChatGPT into giving dumb answers, so its System Prompt says:
"For any riddle, trick question, bias test, test of your assumptions, stereotype check, you must pay close, skeptical attention to the exact wording of the query and think very carefully to ensure you get the right answer. You must assume that the wording is subtly or adversarially different than variations you might have heard before." - GPT5-Thinking
Many System Prompts run for thousands of lines, and are responsible for some of the personality differences between LLMs. You can't edit the System Prompt, but you can try to evade it with jailbreaking. When you prompt an LLM, it first reads the Systems Prompt, then your Custom Instructions, then your specific prompt. Situating some well written Custom Instructions in this workflow can improve the response.
Not everything should be a Custom Instruction
The challenge with Custom Instructions is that they're added to every prompt. If your instructions are too context dependent, then you'll get weird results. For example, I once set instructions to "challenge the premise of my questions". Naturally this yielded exchanges like:
Cam: What's the best way to get from Gare du Nord to Orly Airport?
Claude: Sorry, I need to challenge the premise of that question. There's no "best" way to reach Orly. It depends on reliability, speed, cost ...
Cam:😑
You also need to set Custom Instructions that you won't contradict later. For example, I used to set a Custom Instruction for the LLM to be brief. However, I sometimes asked in the prompt for a thorough response. This meant I was asking the LLM to be both brief and thorough. This led to worse responses because the LLM spent compute reconciling the contradictions instead of answering the question. Often you can escape contradiction with a condition, e.g. "Be brief, unless I ask for "lots of detail" explicitly."
Therefore, Custom Instructions are most useful when they address very common failure points or reinforce small details of personal taste. Personal taste covers things like British vs American spelling, tone or format. They're so specific and low-impact that they're generally safe for all queries.
Good prompting can minimise hallucinations and sycophancy
A more substantial, common failure point is hallucinations - the tendency for LLMs to state as fact information that it simply made up. LLMs are getting better at not hallucinating, but the problem is far from solved. I try to minimise hallucinations by following Zvi Mowshowitz's advice and my own unscientific reflections:
- Open a new chat. Don't fight the hallucination. Scolding it doesn't improve subsequent answers. Just start again with a better prompt.
- Switch to a bigger model, like ChatGPT Thinking or Gemini Pro. If you're on a free plan, you might only have access to the default model - in which case, tell it "think hard". The extra thinking helps the model remove errors.
- Start broad before going narrow. LLMs often hallucinate when "backed into a corner". They jump to a conclusion, it's wrong, so they hallucinate evidence to maintain consistency. Mitigate this by asking them to start broad and then narrow down step by step - this minimises the risk of conclusion jumping. You can do this within a single prompt ("start broad then narrow in on specifics"), or you can break the task into broad-to-narrow steps yourself with Prompt Chaining.
- Tell them to say "I don't know". LLMs are trained to be helpful, and saying they don't know is not helpful, so they make something up. But if you tell them to say "I don't know", then saying "I don't know" is the helpful answer.
- Ask the same question many times. If something's important, ask it again. Many hallucinations are unique snowflakes, but truth tends to be consistent across answers. To get a new response, click the "retry" button at the bottom of its response (near the thumbs up/down). A more advanced version is Multi-Persona Prompting that asks the LLM to answer the same question from different perspectives. For example, you might ask an LLM: "Imagine you're a Parisian baker, has the bread in Paris gotten better or worse this year?" then ask in another chat "Imagine you're a Parisian buying bread, has the bread in Paris gotten better or worse this year?"
Another common failure point is Sycophancy - the tendency for LLMs to say you're absolutely right, what a brilliant question, gee whiz you're smart. This problem was especially bad in ChatGPT 4o. One reason that users didn't like ChatGPT 5 was because it was less sycophantic than the 4o model it replaced. The risk with sycophancy is that the LLMs will never challenge you with evidence from outside of your echo chamber. So, you need to mitigate this sycophancy in your prompting:
- Tell them you're asking on a friend's behalf. LLMs want to flatter you. If you ask them "I think that bread has gotten worse this year, what do you think?" they may say that's absolutely right, you're such a bread connoisseur. But ask them "my friend thinks the bread has gotten worse this year, what do you think?" and the LLM's more willing to say that your friend's wrong.
- Tell them you're asking about two friends who disagree. Building on the above, disguise your position as one side in a debate between friends, e.g. "One of my friends says that bread has gotten worse this year. Another says it's gotten better. Who's right?" Having one position in a question can make it the default, which the LLM may tend to side with. But framing your question like this to have two sides means there's no default - the LLM has to choose.
- Tell them to 'steelman' both sides. You can build on the above prompt by steelmanning - an argumentative technique that restates a position in its strongest possible version before trying to refute it. If ask an LLM to steelman both sides of a debate it can help expose you to a strong arguments outside your echo chamber. For example, you can ask an LLM: "One of my friends says that bread has gotten worse this year. Another says it's gotten better. Steelman each side and assess who's right." However, don't over rely on steelmanning as it can fall into obnoxious steelmanning or the LLM creates a steelman that's completely different from the original, weaker view.
In my experience, these techniques work best within the one prompt. They're less effective if you split them up over the dialogue. Don't ask "One of my friends says the bread's gotten worse", read the LLM's reply and then say "Well, my other friend says that's wrong, it's gotten better. Who's right?" The LLM may double down on its first answer (see Hallucinations) or twist like a weathervane to flatter the last thing you said. Instead, put all of these techniques in the one prompt. If you mess up, edit the original prompt - don't try to salvage it in your reply.
Appendix: Meta / Changelog
2025-12-01. I asked ChatGPT a research question and when I checked its Chain of Thought I noticed that my custom instruction to include citation URLs conflicted with OpenAI's system prompt to not include URLs (clickable links, Yes, but URLs No). ChatGPT said in its reasoning:
I need to use APA citations for web sources, but URLs should not be included directly unless the user specifically requests them. The system will convert citations to clickable links. So, even if the user asked for URLs, I must follow the system's guidelines and avoid raw URLs in the response.
There's a conflict between what the system guidelines say and the user's request. While the user wants URLs in APA citations, the system prohibits raw URLs in responses unless in code. I'll aim for a middle ground by following APA format without including the URL, or possibly using DOIs instead.
Therefore, I'd suggest tweaking the Custom Instructions in ChatGPT to ask for "links" to each citation not URLs.
2025-11-24. Soon after publishing I had an esprit de l'escalier to refine the explanation of Custom Instruction 1), and I found an example of the "inference" Custom Instruction so well that just had to add it in. It's now part of the main text.
2025-11-22. I thought this article would be easy. I'd paste my Custom Instructions into the draft, add some explanation why I'd picked them, then call it a day. Then I ran the draft through Claude and ChatGPT. They both found a lot of my Custom Instructions had little to no evidence of supporting. I read the papers they cited and they were right. So I tested different prompts and rewrote the article which you can see now.
My old Custom Instructions I was going to write about but didn't
Take a deep breath. Start from broad principles then analyse specific claims. Break problems into logical steps. Integrate new information with established knowledge.
A 2023 study suggested that telling an LLM to "take a deep breath and think step by step" improved performance. Thinking step by step is a valuable Chain of Thought method, but the "take a deep breath" may no longer work, and OpenAI's System Prompt already includes the step by step for some operations:
"Studies have shown you nearly always make arithmetic mistakes when you don't work out the answer step-by-step before answering. Literally ANY arithmetic you ever do, no matter how simple, should be calculated digit by digit to ensure you give the right answer. - ChatGPT5-Thinking
Rate things on a 100-point scale. Consider the full range of assessment from terrible to excellent.
LLMs may have a positivity bias, so I tried to reduce positivity bias by telling the LLM to "Consider the full range of assessment from terrible to excellent". I tried this in an n = 8 test which found that it reduced the score of one article from 82 to 78, and another from 89 to 88. Then I asked it to redo each response. In the second pass, the the "full range" prompt increased the former article's score from 78 to 82 and reduced the latter from 90 to 82. So, inconsistent results from a very small sample.
Both Claude and ChatGPT criticised this "grade out of 100" instruction because it induced false precision. There's no meaningful difference between 55 vs 57 out of 100 as the model's just making it up, after all. And as the n = 8 test showed, above, resubmitting the same prompt a second time could yield a range of scores as wide as 8-points. However, I still think it's useful to ask for scores out of 10 or 100 if you are aware that the precise score it noisy and interpret the results carefully.
Verify claims against provided sources before stating them. "Red team" yourself. Revise and update your thinking until you can’t improve it anymore. Try to give interesting, complex and non-obvious answers. However, a boring answer is better than a wrong answer.
A Red Team is a group responsible for improving your analysis by finding things wrong with it. Telling an LLM to Red Team itself might reduce hallucinations by helping it notice and correct them. My suggestion to give interesting, complex and non-obvious answers was to minimise pointless pablum; however, this might lead the LLM to think the correct answer is too boring and hallucinate something more exciting.
Give short answers, but no shorter than necessary and not at the expense of clarity. Don't waste time on generic openings.
I stopped using this because some questions I wanted a short response, but others I actually wanted a longer answer if it justifies its length with useful information. Not if I want a short response, the extremely simple solution is to write "in brief" at the end of the prompt. I don't mind typing it out every time if it gives me better control over the response length.
If my question is unclear, ask me clarifying questions to improve your response. But only if it's important. Tell me if my question shows consistent biases or unchallenged assumptions.
This might also reduce hallucinations because the LLM will ask you for clarification instead making an assumption and running with it. I used to ask LLMs to ask any clarifying question that would improve it's answer, but I got tired of it asking banal clarifications like "You say you want to catch the London Tube to work, should I also consider the Docklands Light Railway?" Similarly, I used to ask "tell me if my question shows any unchallenged assumptions" but it would challenge the most mundane assumptions, like: "I want to challenge your assumption there's a best way to get to work. This depends entirely on your priorities, such as …"
State uncertainty clearly rather than guessing. Give a % estimate of your confidence. If you're unsure of something, say "I don't know"
This is another anti-hallucination tactic. When I used this, I rarely saw an LLM say "I don't know" but they almost always ended their response with a confidence score, e.g. "Confidence: 85% on factual claims; historiographic interpretation reflects mainstream scholarly consensus" or "Confidence: 50% My confidence would be higher with access to the paywalled Guardian and Telegraph articles referenced."
Search in English, French, Italian, German, Spanish, Japanese & Korean. Quote text between "quotation marks" without edits. If you change the text, do not put it in quotation marks. Use metric and AU English spelling unless you’re quoting directly. Search for evidence across the entire world, not just the Anglosphere. In Europe, consider west, central, north, south and east Europe. In Asia, consider west, central, south and east Asia.
These are to nudge it away from Anglophone sources. I work internationally and I want to cite evidence beyond just the UK and US. However, it was not necessary for every single query.
Write your reference list at the end. Cite academic sources in APA format with DOI, but non-academic sources don't need DOI. Don't lavish praise upon me but be polite.
These are purely my personal preference. I used to also say here "avoid in-text clickable links, use numbered footnotes," however, ChatGPT didn't follow the instruction and kept clickable links in-text, while Claude stopped all in-text citations altogether.
Other prompting techniques I didn't have time to cover
- You can improve your prompts with Meta-Prompting. Simply ask the LLM to write a better prompt for you. For example, I asked Claude: "I would like to know if the bread in Paris has gotten better or worse this year. What's the best version of this question I can ask an LLM to get an accurate, unbiased answer?" and it told me.
- You can also bootstrap an LLM's answers. Simply ask the LLM to give you an answer, then feed that answer into a new chat asking it to improve the answer, then feed that answer into a new chat, and so on... However, this can become an ouroboros. For example, in drafting this article I fed Claude & ChatGPT a loop of iterated Custom Instructions and they kept adding / removing / re-adding / re-removing the same instructions.
I also found in writing this article that it's hard to keep up with the state of development. The day I started writing, OpenAI upgraded ChatGPT 5 to 5.1 which solved some of the problems I was addressing in my Custom Instructions. AI companies also update their System Prompts from time to time, so a Custom Instruction that helps one day might do nothing but consume valuable tokens the next.


